Cet article m’est venu, car il est fréquent que l’on entende ou lise, des abus de langage sur le SEO, qui pour ma part me font un peu grincer des dents.
Ne pas confondre le crawl et le scroll
Qu’est ce que le scroll ?
Le scroll est humain ! C’est l’action de défilement des pages web de haut en bas. Ce sont donc les utilisateurs qui scroll avec leur souris, pad ou avec leur petits doigts sur des appareils mobiles.
Qu’est ce que le crawl ?
Le crawl est soit une nage 😉 soit le passage des robots des moteurs de recherche sur un site. C’est l’action d’un robot qui vient visiter vos pages en passant de lien en lien pour stocker les informations de vos pages, afin de les analyser et leur faire subir quelques tests de pertinence, qualité, rapidité etc.
Le crawl des robots d’indexation sur un site est la condition sine qua non pour la lecture de vos pages par les moteurs de recherche.
Ne pas confondre la balise title et l’attribut title
Les deux existent, mais n’ont pas la même fonction.
La balise Title
La balise Title, est un des éléments obligatoires d’une page HTML au même titre que les balises (ou éléments) : <html> <head> <body>
En SEO, la balise title est un des éléments d’optimisation incontournable… peut être le plus important.
Cette Balise title (qui n’est pas une méta-donnée) est affichée tout en haut de votre onglet de navigation. Vous pouvez également la retrouver sur la liste de résultat des moteurs de recherche.
L’attribut Title
L’attribut Title est comme son nom l’indique un attribut de balise HTML. L’attribut title peut se rattacher à différentes balises : La balise de lien <a> </a>, la balise d’image <Img /> etc. Cet attribut n’a pas réellement de poids en référencement naturel. Pour que cet attribut soit visible un élément de pointage est obligatoire (souris).
Pour mémo :
Une balise est toujours représentée par des <> exemple <title>, alors qu’un attribut se glisse dans des balises HTML exemple <a href= « # » title= « mon title »>
La balise alt ça n’existe pas !
Depuis 2005, je combats cette « balise ALT » ! Qui me fait saigner les oreilles à chaque fois.
Une balise alt ça n’existe pas. Le ALT est un attribut de la balise HTML <img> et seulement la balise image, il n’y a pas de alt sur les liens (balise <A>).
Cet attribut alt, ou encore Alternative textuelle de l’image, permet de maintenir l’information qui se trouve, ou passe par une image. C’est un attribut extrêmement important pour l’accessibilité, afin que les personnes en situation de handicap visuel puissent avoir la même information que les utilisateurs lambda.
En HTML l’attribut alt est obligatoire, ceci veut dire que votre CMS doit impérativement placer cet attribut dès qu’une image est insérée. Le contenu de cet attribut doit être défini par vos soins, afin de décrire l’information qui passe par ce média.
- Une image purement illustrative ne devrait pas avoir une alternative renseignée ;
- Une image affichant du texte doit impérativement avoir une alternative avec ce texte qui peut être complété si besoin ;
- Une image support de lien, doit impérativement avoir une alternative, servant alors de libellé de lien.
Éviter de « blinder » vos alternatives avec des mots clés, ceci ne vous apportera pas grand chose pour le SEO, et va surtout gêner des personnes qui ont réellement besoin de ces informations pour comprendre vos contenus.
L’indexation et le crawl
Nous l’avons vu le crawl, est l’action de visite des pages d’un site par les robots des moteurs.
L’indexation est la prise en compte des pages d’un site pour affichage sur la liste de résultat des moteurs (SERPS).
Il est important de bien faire la différence, afin de pouvoir maîtriser et les interdictions de crawl et interdictions d’indexation.
Pour interdire le crawl d’une page, il faut alors poser la directive « disallow » dans le fichier robots.txt. Interdire le crawl n’empêche pas l’indexation ! Si votre page possède des Backlinks, alors Google peut passer outre votre directive et indexer la page.
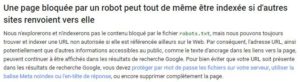
Dans ce cas la description du résultat sur Google indiquera :

Le robots.txt indique donc aux robots des moteurs qu’ils n’ont pas la possibilité de lire la page, et généralement les robots dignes de ce nom font demi-tour lorsqu’ils voient cette directive.
Sans crawl par de lecture des interdictions d’indexation !
Si vous indiquez aux moteurs, des pages à ne pas indexer (ne pas inclure dans les résultats de SERP) par le biais d’une balise robots noindex sur vos pages, il est alors important de laisser les moteurs crawler / lire ces pages pour qu’ils puissent suivre vos directives.
Si ces mêmes pages sont bloquées par un fichier robots.txt : comment le moteur peut alors voir la balise qui se trouve dans votre code ?
Pour interdire l’indexation, il est également possible de donner la directive par le biais de l’entête HTTP X-robots-tag, ou en plaçant un login et passe (méthode recommandée pour protéger vos espaces de développement).
On peut retrouver ces confusions dans la mesure d’audience, ce qui fera surement l’objet d’un prochain article !